PANGeA
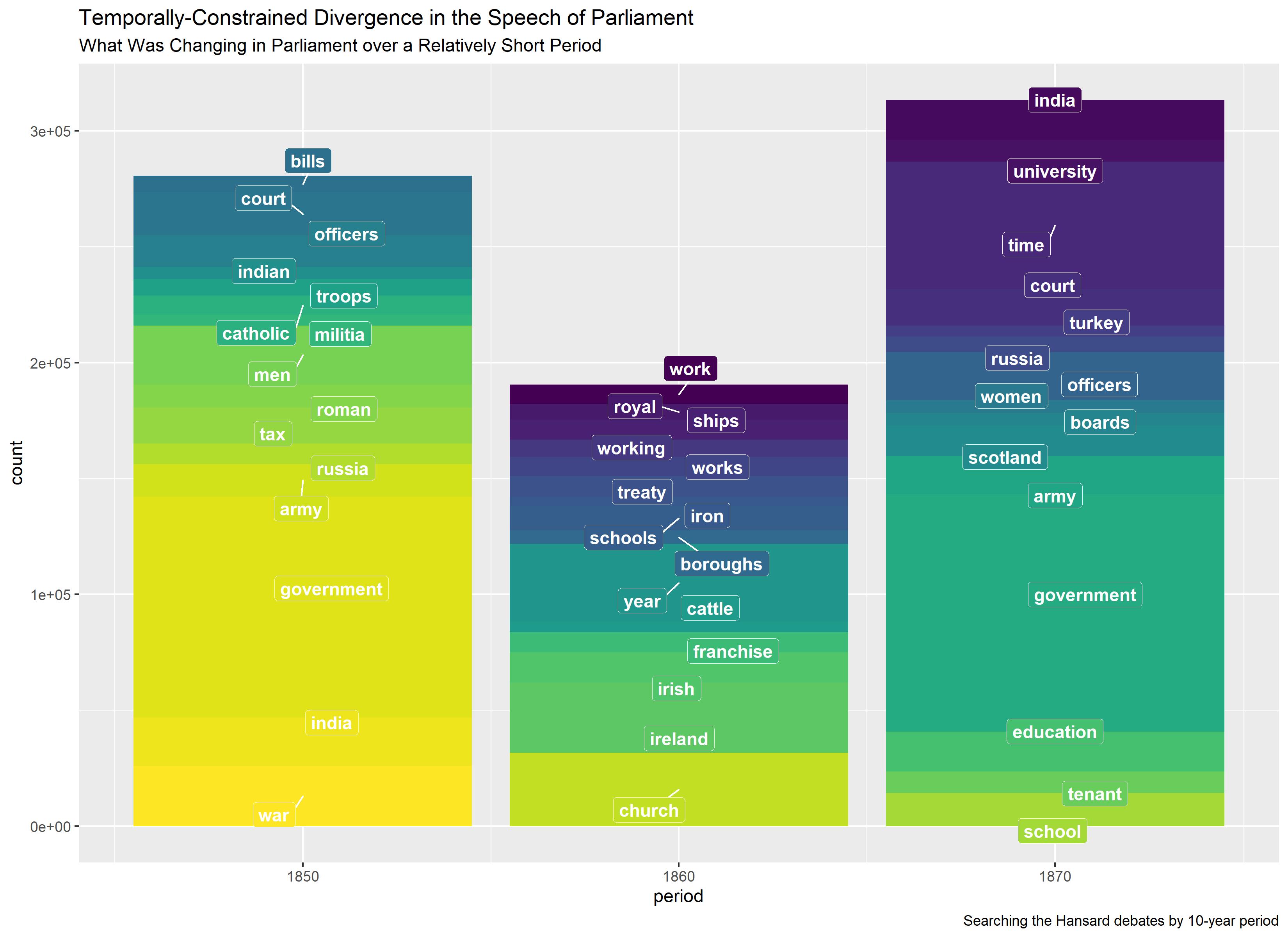
PANGeA is a system that uses large language models (LLMs) to create narrative content for turn-based RPGs based on game designers' high-level criteria. It introduces a novel validation system for handling free-form text input during development and gameplay, employing "self-reflection" techniques, enabling small/local LLMs to perform comparably to foundational models. It enriches player-NPC interactions by generating personality-biased non-playable characters (NPCs). It improves AI accuracy through crowdsourcing mechanics. PANGeA houses a server with a custom memory system that provides context for LLM generation. The server's REST interface enables integration with any game engine.