
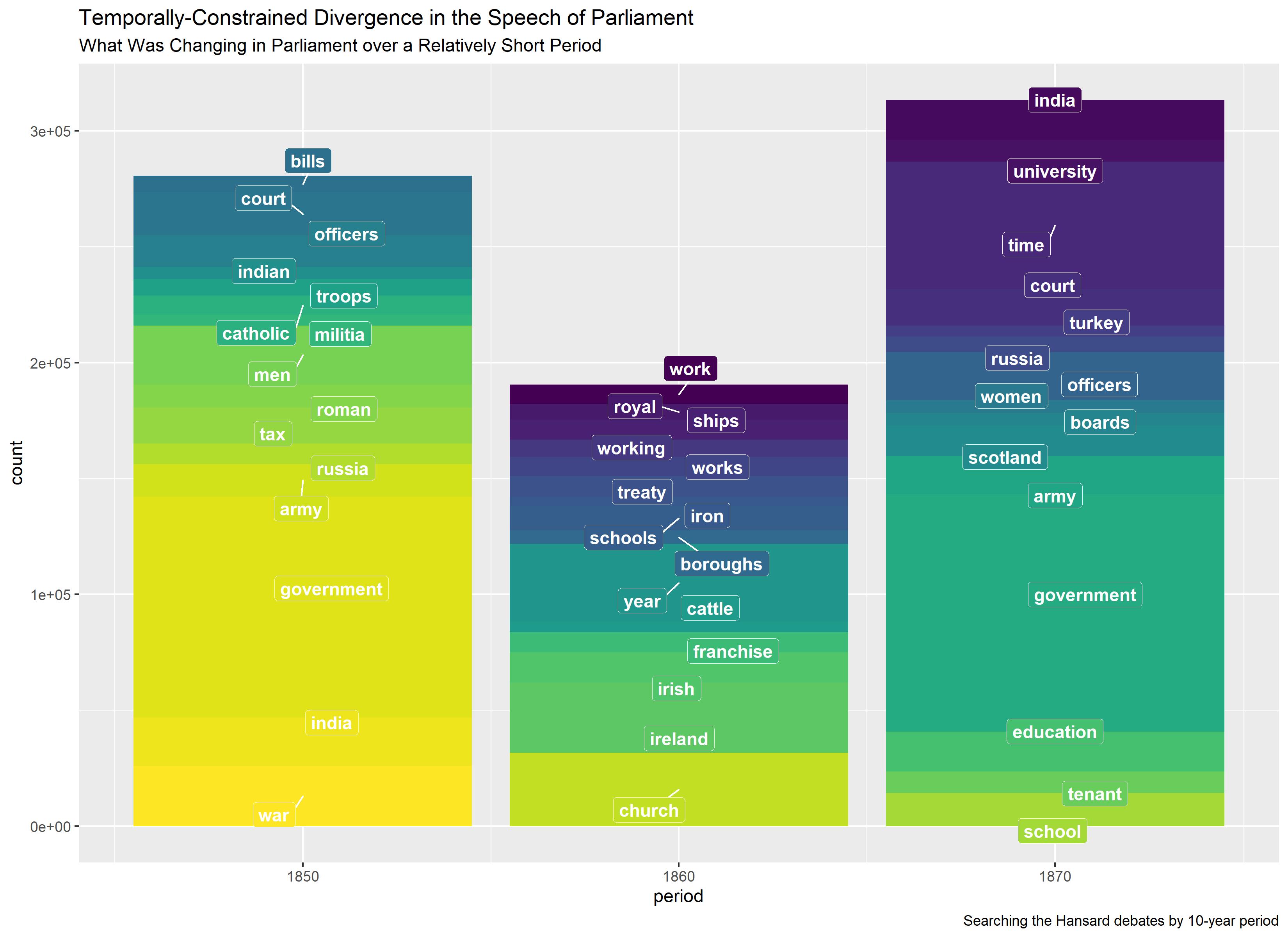
We present “The Hansard 19th-Century British Parliamentary Debates with Improved Speaker Names: Parsed Debates, N-Gram Counts, Special Vocabulary, Collocates, and Topics.” Our intention is to provide researchers with an analysis-ready version of the 19th-century Hansard debates (and supplementary material) to enhance analyses of the era.
We made two major improvements while creating this corpus: we identified debates that had missing entries in UK Parliament’s records and we added a field for the names of disambiguated speakers. Our process for disambiguated speakers is recorded as a separate project, here .
To discover missing debates we identified systematic issues within Parliament’s digital version of Hansard where XML tags were missing or erroneous. Debate text, for example, might be tagged as a debate title or as a speaker. In other cases, sections were missing tags in their entirety. While the mistagged data was merely buried, not lost to time, the errors in the XML tags were problematic enough to cause the data to miss being indexed by UK Parliament, and to result in missing entries from the corpus.
Automated scripts for producing our corpus can be found on our repository . An article
This work was supported in part by National Science Foundation (NSF) Grant (no. 1520103).
{kind=link}