Text Mining for Historical Analysis
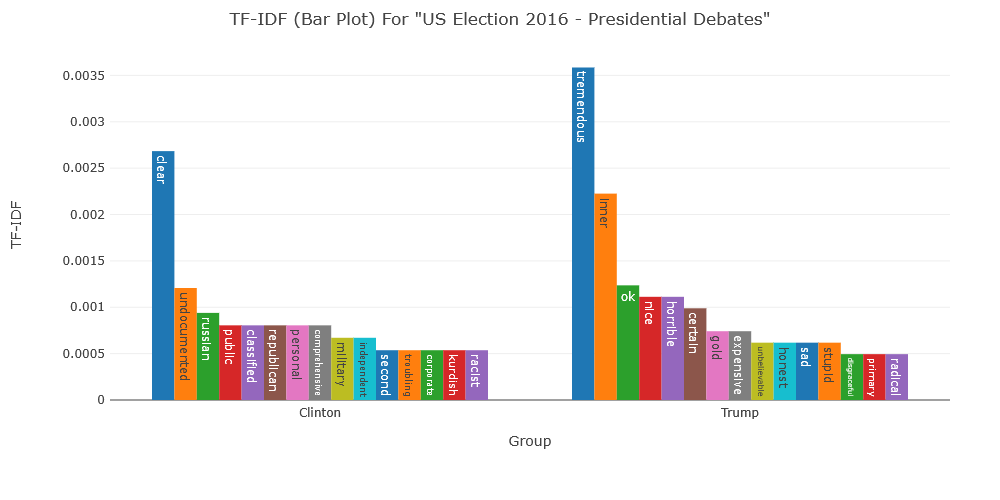
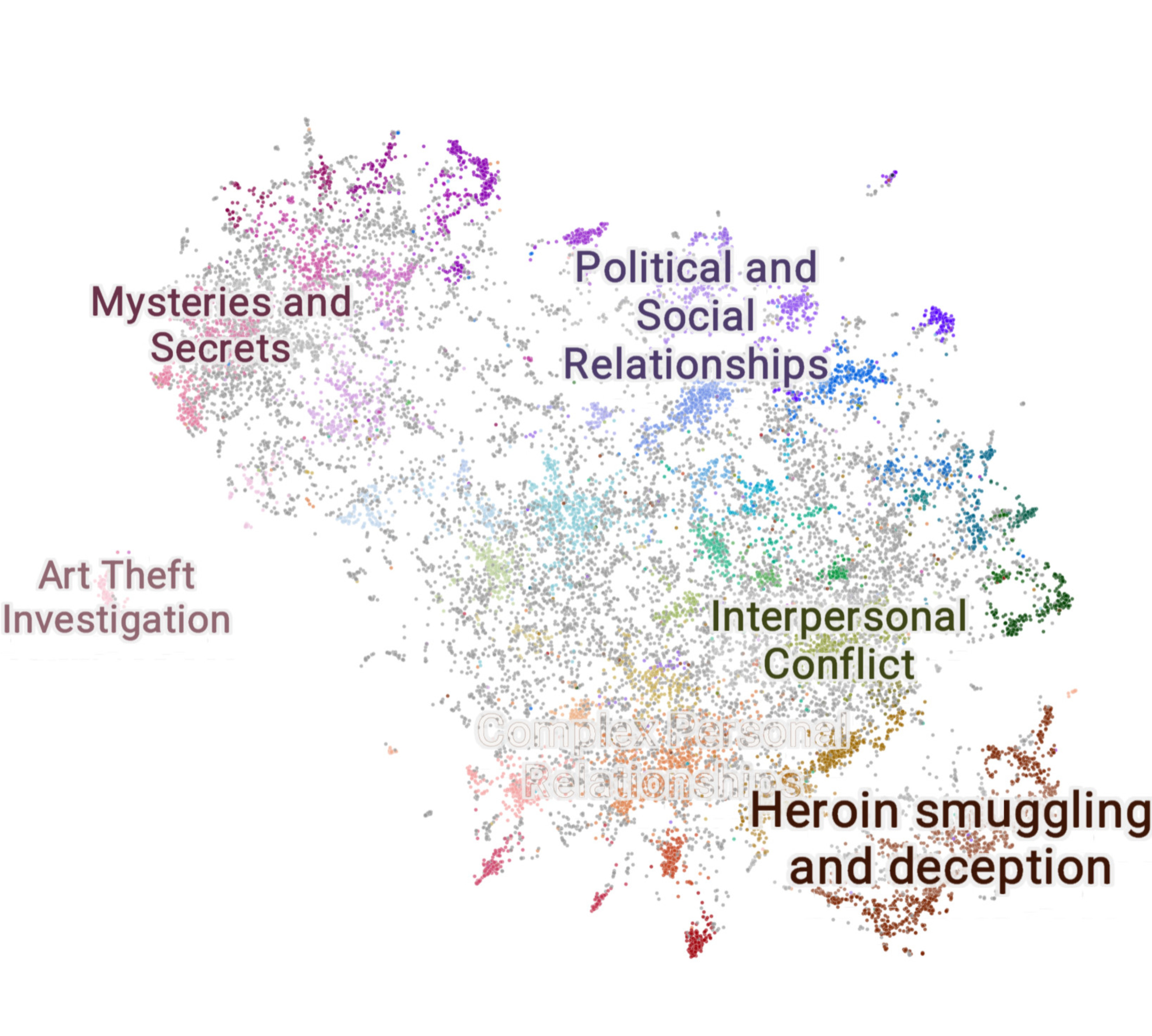
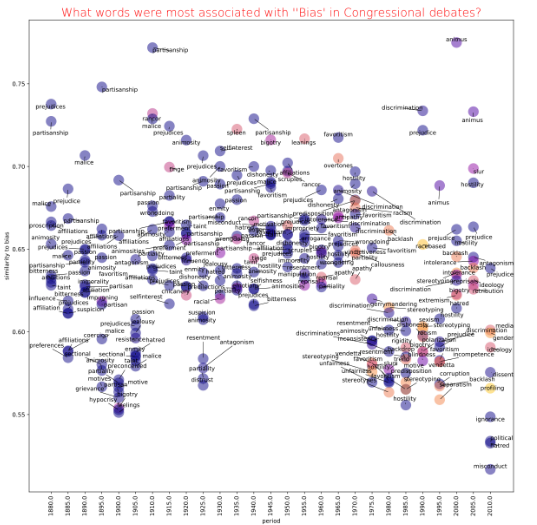
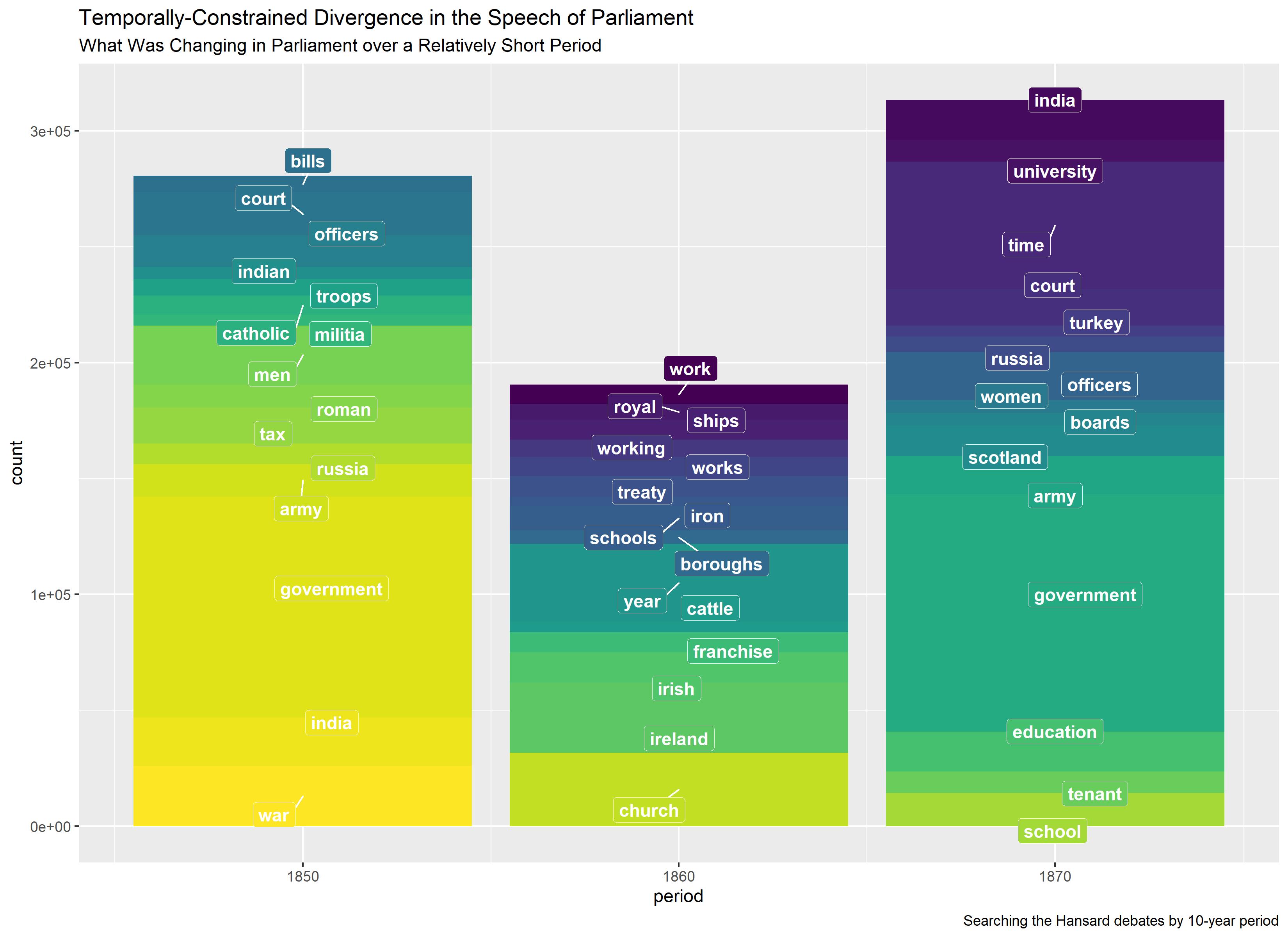
Text Mining for Historical Analysis offers a critical intervention into the evolving field of digital history. It introduces "computational historical thinking"-a mode of thinking that explores the epistemological entanglements between computation, theory, and historical analysis, emphasizing how computational procedures actively shape the questions we ask and the meanings we derive from data. Through sustained engagement with historical corpora—such as the 19th-century Hansard debates and contemporary U.S. Congressional Records—this book demonstrates how to attend to both structure and semantics, thus reimagining the relationship between computation and historical knowledge in the digital age.