
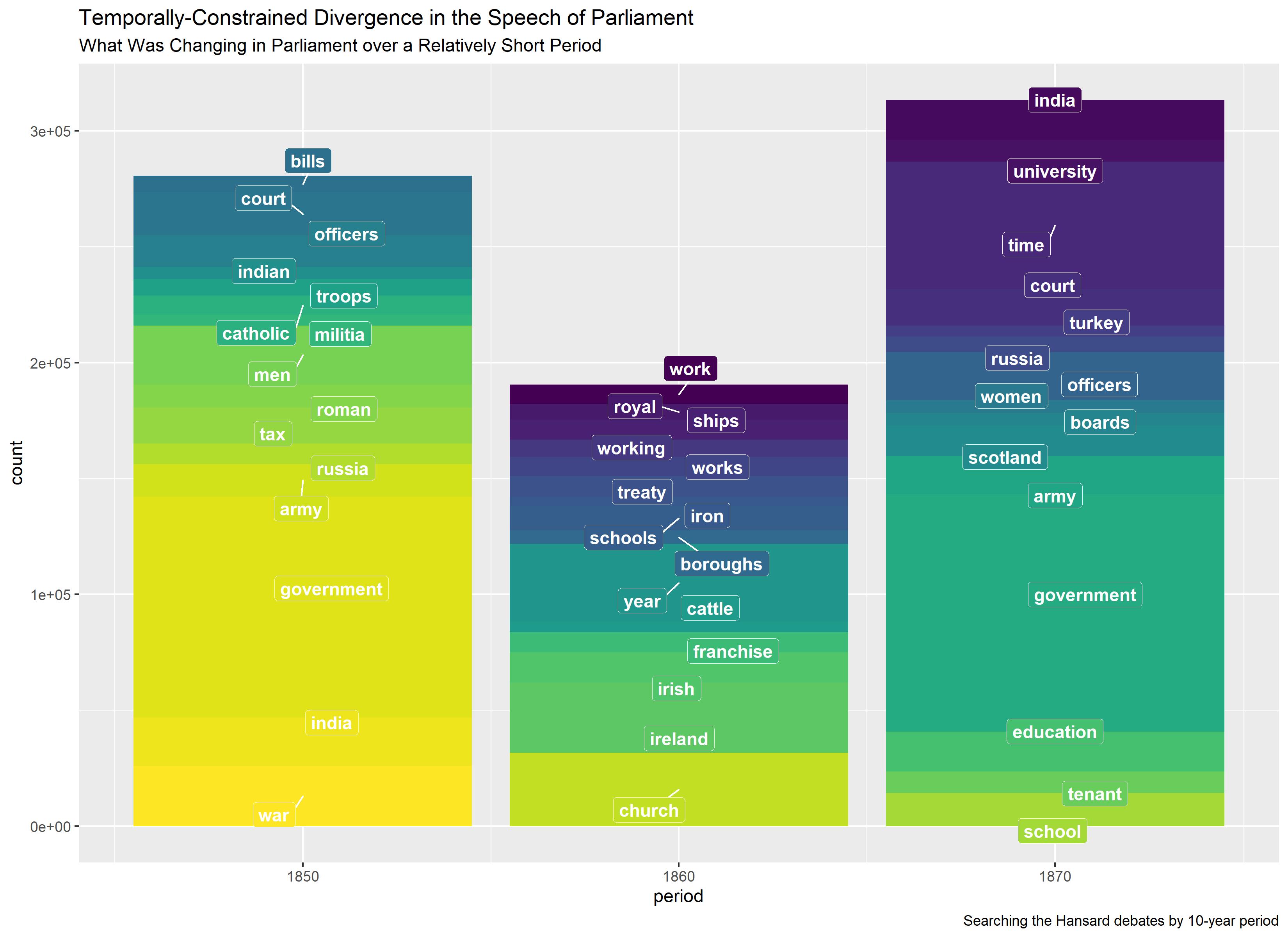
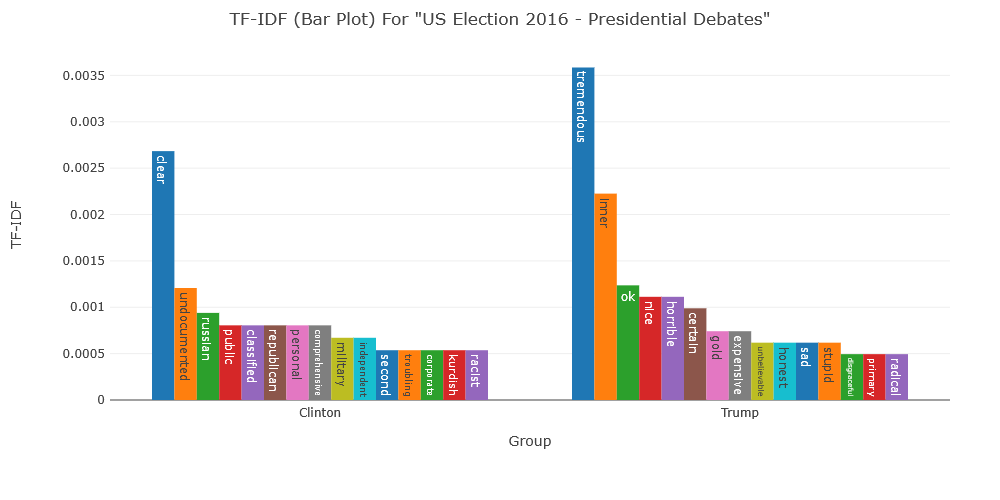
In recent research, extracted triples have become increasingly important for the analysis of large, textual corpora. By giving insight into the linguistic features of a corpus, extracted triples have supported rich interpretations of some of the most relevant problems of our time. They have been used to track the development of anti-vaccination narratives originating on “Mommy Blogs” (Tangherlini et. al, 2016), descriptions of climate change across online news sources (Alashri et al., 2018), to model scientific literature on COVID-19 (Papadopoulos et. al, 2020), and to trace how Parliamentary discourses on the rise of peoples’ rights have changed over time and may be influencing the politics of our present moment (Guldi, 2022).
The growing importance of triples extraction for analyzing large corpora has put the quality of extracted triples under new scrutiny, however. Triples outputs are known to have large amounts of erroneous triples. The need for a method of triples extraction designed for textual analysis is clear: the extraction of erroneous triples poses a risk because erroneous triples can be unfactual and even analogous to misinformation. Disciplines such as history, literature, and the social sciences, rely on accurate representations of events. In some cases, misrepresentations of language can be as problematic as describing a historical event that never occurred.
The present research proposes a method of triples extraction, posextract, which has been designed to meet the increasing need for high-accuracy triples outputs for the analysis of text. We propose a solution aimed at reducing errors related to: a) ungrammatical extractions; b) double counting; and c) the missed detection of triples.
Software package coming soon Article coming soon

{kind=link}